K Means 4 Tone
Finding dominant colors in an image using k-means in golang.
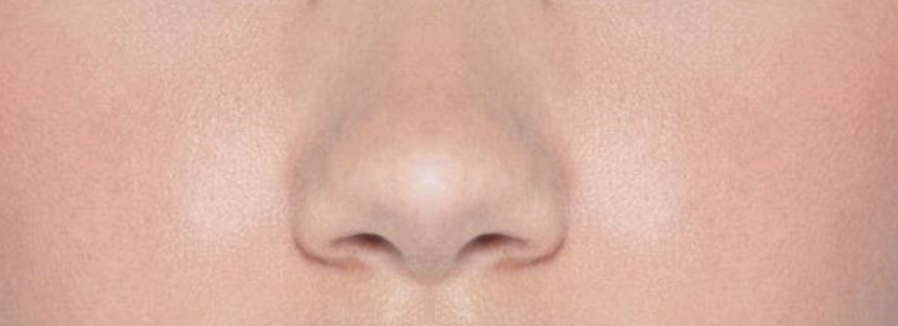
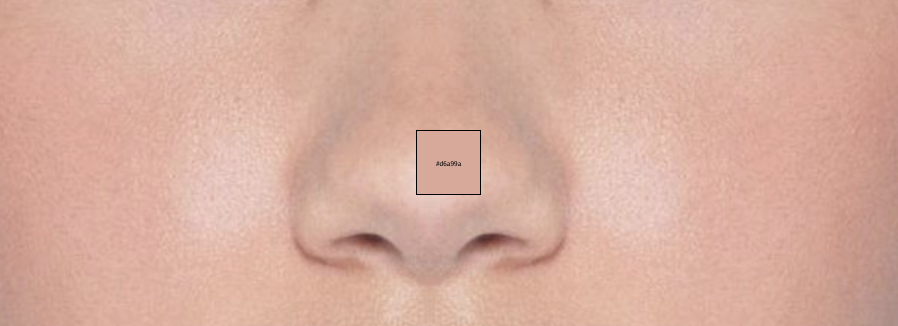
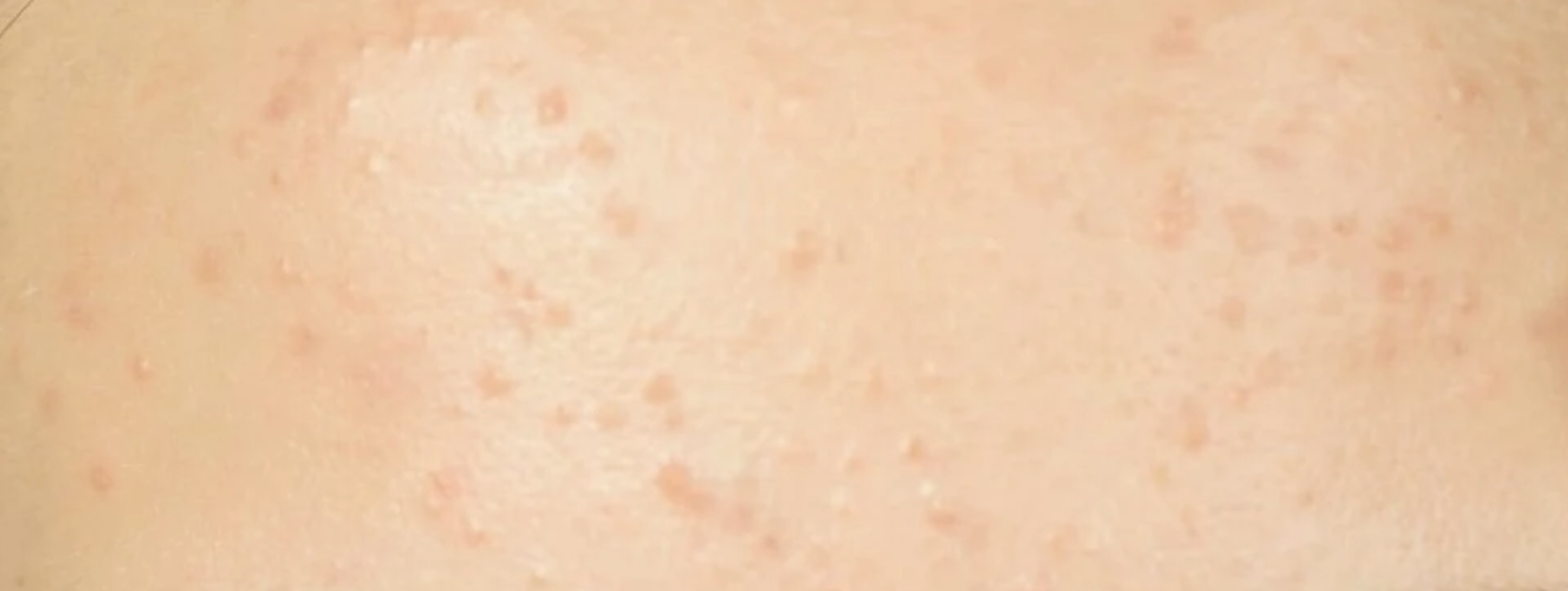
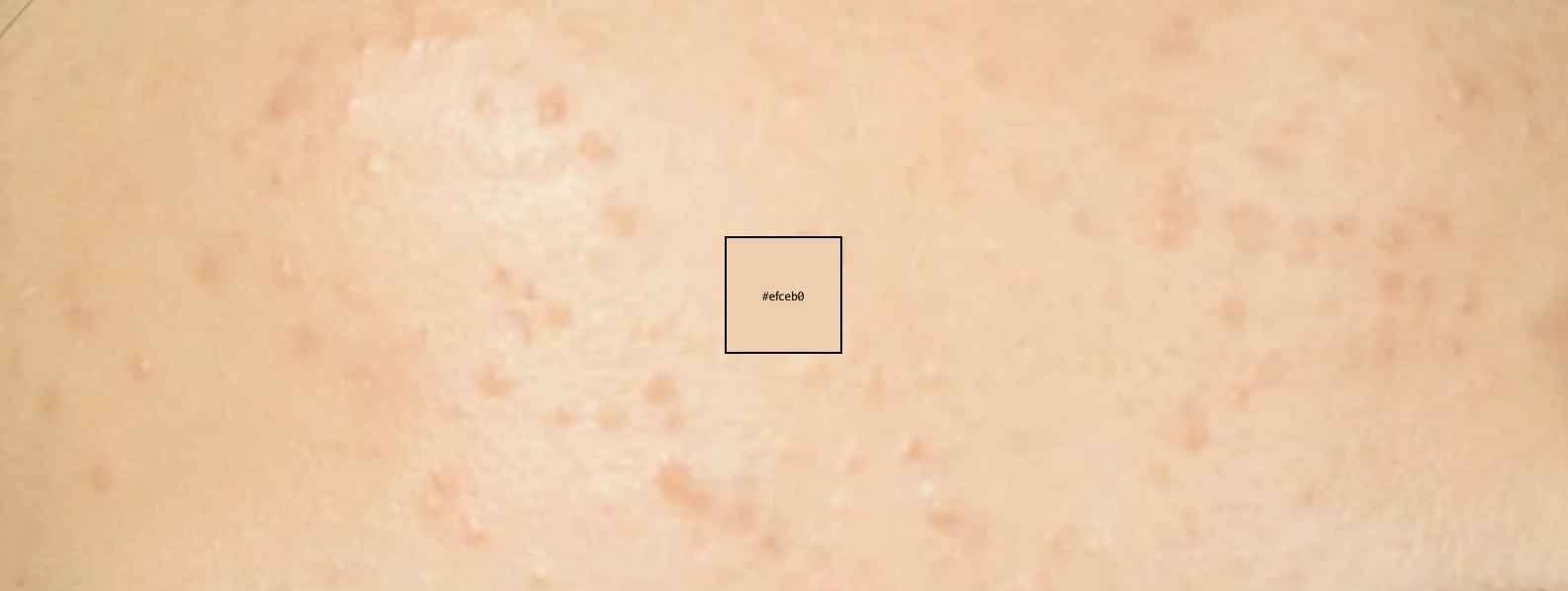
Hello friendos. Today we’re going to explore the intriguing world of image processing with golang. At the end of this blog post, you’ll find a well commented implementation for how to find the dominant colors in an image using the KMeans Clustering algorithm. I’m going to use this algorithm to create a makeup palette based on the dominant skin-tone colors in an image. I have included a couple of examples below.
Images and Pixels
Before we jump into the algorithm, let’s lay down some basics. Every digital image is made up of tiny elements known as pixels. Each pixel has a color, and the entire image is a combination of these colored pixels. The color of a pixel is typically represented in the RGB color space, meaning each color is a combination of Red (R), Green (G), and Blue (B), each ranging from 0 to 255.
So what is KMeans Clustering?
Well, now let’s introduce the KMeans Clustering algorithm. This is a type of machine learning algorithm that is used for clustering, i.e., grouping data points into subsets (clusters) based on their similarities.
Imagine that you’re a teacher, and you have a class of students with different heights. If you wanted to group these students based on their height, one way to do it would be to find the average height, say it’s 5 feet. You could then say that anyone below 5 feet is “short,” and anyone above is “tall.” That’s exactly what KMeans does, but with more complex data and multiple groups!
Step by Step Guide to KMeans Clustering
Here are the simple steps KMeans follows:
1. Initialization
Decide on a number ‘K’ for the number of clusters you want. This could be any number based on your needs. In our case, ‘K’ might represent the number of dominant colors we’re interested in. Next, KMeans randomly selects K points in our data as the initial “centroids,” or cluster centers.
2. Assignment
Each data point (in our case, a pixel color) is assigned to the nearest centroid, and they form a cluster. The ’nearest’ is calculated using a method such as Euclidean distance in the RGB space.
3. Update
For each cluster, we calculate a new centroid by finding the average of all the points (pixel colors) in the cluster.
4. Repeat
We repeat the assignment and update steps until the centroids do not change significantly anymore, indicating that our clusters have stabilized.
And that’s it 💖! You’ve now successfully grouped your data using the KMeans algorithm.
Applying KMeans to Images
When it comes to images, each pixel’s color in the RGB space can be thought of as a data point in a 3D space (R, G, B). So, if we want to find the dominant colors in an image, we can use KMeans to cluster the pixels. The centers of these clusters will then represent the dominant colors in our image. The larger a cluster, the more dominant its color is in the image!
Remember, the choice of ‘K’ is crucial as it represents the number of dominant colors we want to find. If we choose K = 5, the algorithm will return 5 dominant colors from the image.
Breaking the Infinite Loop in KMeans
While writing and running KMeans code, you may encounter a curious event where your algorithm seems to run forever, caught in an infinite loop. Don’t worry, you haven’t stumbled into a coding twilight zone, this is a known quirk of the KMeans process. Let’s understand why it happens and how to deal with it.
In KMeans clustering, our algorithm is essentially trying to find ‘K’ points, called centroids, that best represent our data. We start with random centroids, assign points to the closest centroid to form clusters, then adjust the centroids based on the points in each cluster. We keep iterating these steps until our centroids no longer move, indicating they have found their optimal place.
However, sometimes these centroids just can’t sit still. They keep shifting around because, with each iteration, different points may be closest and the average (the new centroid) changes. This leads to a situation where the algorithm runs endlessly, trying to find that perfect spot, leading to the dreaded infinite loop.
So, how do we prevent this from happening? Well, we apply a simple but effective solution - we set a maximum limit to the number of iterations. This limit is a parameter you can adjust. After a certain number of iterations, even if the centroids haven’t found their “perfect” spot, we tell our algorithm to stop and accept the best solution found so far. A common choice for this limit is a few hundred iterations, like 300 or 500. This ensures our KMeans algorithm always finishes in a reasonable time, while still giving the centroids a fair chance to find good cluster centers.
Wrapping Up
And there you have it! You’ve just learned the basics of the KMeans Clustering algorithm and how to apply it to find dominant colors in an image. Pat yourself on the back; you’ve stepped into the fascinating world of image processing and machine learning. The power of these techniques opens up endless opportunities. So keep exploring, and keep experimenting 🧪
Here are a couple of examples of the KMeans algorithm in action, to find a good concealer/foundation shade for your skin tone.